Нейросети генерируют видео: как это работает и где попробовать самому

Генерация картинок за два года показала большой прогресс, а с видео дела пока обстоят не очень хорошо.
Компании представляют новые модели для генерации, но мало к каким открывают доступ. Приемлемое видео получить пока трудно. Ролики выходят низкого качества и с многочисленными артефактами. Крупные компании не открывают доступ к своим алгоритмам, а в единственной актуальной открытой нейросети пользователи генерируют абсурдные мемы — для другого ее сложно приспособить.
Разобрались, как работает генерация text-to-video и где попробовать ее уже сейчас.
И независимым. Разбираемся в налогах и правах, ищем жилье и оплачиваем коммуналку

Что такое text-to-video генерация и как она работает
Алгоритмы генерации видео устроены сложнее, чем модели для создания картинок. Если в первом случае нужно сгенерировать одно изображение на основе миллионов других, то во втором требуется последовательность связных и быстро сменяющих друг друга картинок. Например, для пятисекундного видео с частотой 24 кадра в секунду требуется 120 изображений.
Первые шаги в генерации видео по текстовому описанию исследователи сделали в 2022 году. Сразу несколько компаний представили алгоритмы, которые по-разному генерируют видео.
Диффузионные модели работают так: берется картинка, на нее добавляется шум до тех пор, пока она вся не будет шумной. Затем эти изображения соединяют в пару. Из пар «картинка-шумная картинка» создается датасет, на котором нейросеть обучается делать обратную операцию: из шума создавать изображение. Так работает нейросеть для генерации картинок Stable Diffusion.

Если говорить о генерации видео, то работает это так: например, нейросеть Make-A-Video от компании Meta получает текстовый запрос, преобразует его в эмбеддинг — векторное представление данных — и отдает декодировщику, который диффузионным методом генерирует изображение. Но не одно, а сразу 16 — и так, чтобы объекты были согласованы между собой. После этого у набора кадров повышают разрешение и соединяют в видео длиной в несколько секунд.

Make-A-Video обучали только на парах «текст-изображение». А нейросеть Imagen on Google, работающую на диффузионной модели, помимо этого также обучали на парах «текст-видео».
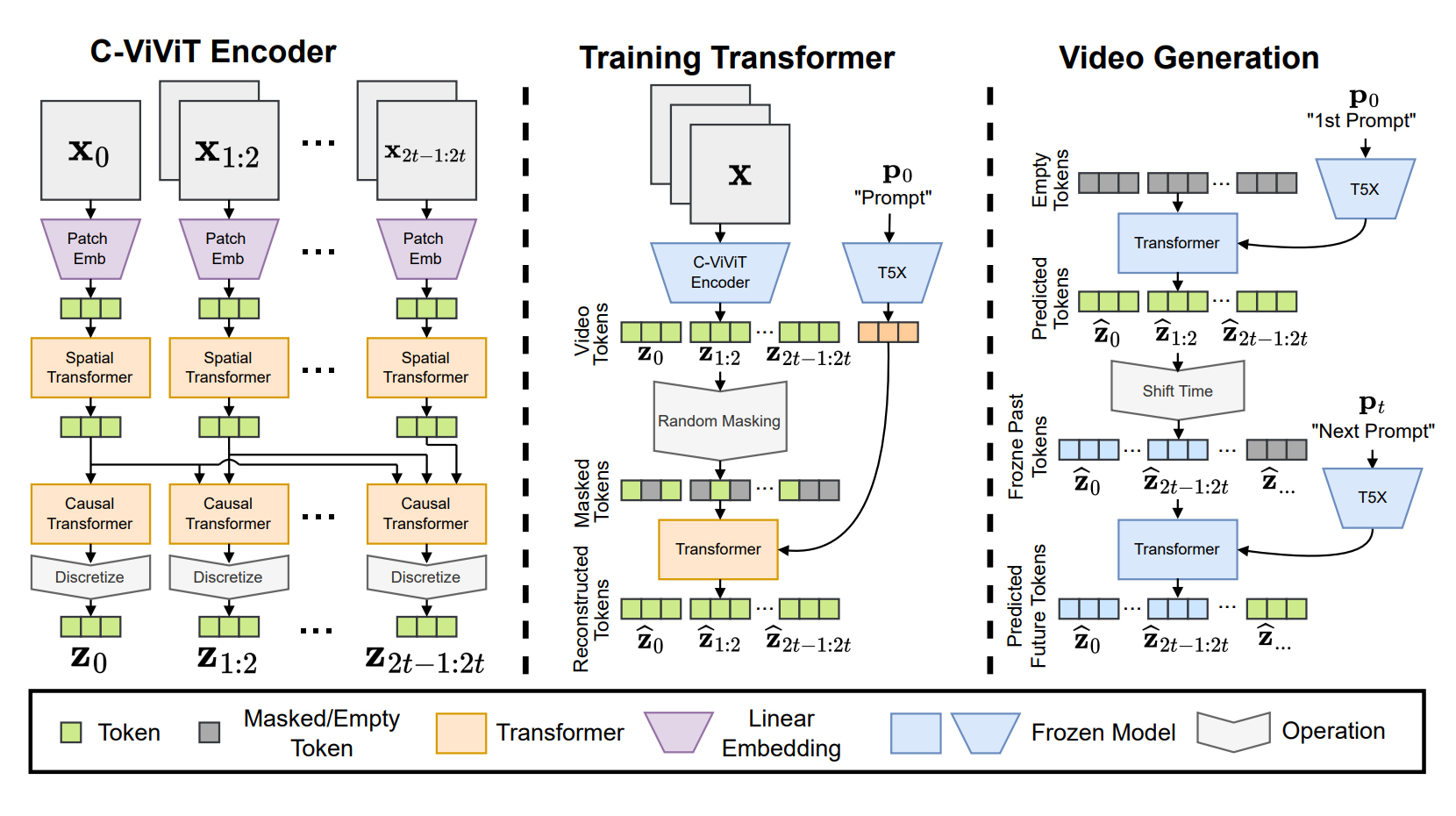
Сложные модели состоят из нескольких алгоритмов. Например, нейросеть Phenaki от Google генерирует видео с помощью кодировщика и нейросети-трансформера. Кодировщик преобразует видео в токены — сжатые данные о ролике. Нейросеть-трансформер анализирует текстовый запрос и создает видеотокен. Затем он превращается в сгенерированное видео, которое соответствует запросу.
В результате получаются длинные ролики продолжительностью до нескольких минут. Они требуют детального описания сцен, а не короткого, как у диффузионных моделей. Phenaki обучали на парах «текст-видео» и «текст-изображение».

Какие модели генерации видео существуют
Большинство моделей недоступно для публики: их тестируют в закрытом режиме внутри компаний. Google, например, переживает о том, что пользователи могут использовать технологию во вред: генерировать фальшивые видео или порно-дипфейки.
Сохраняется и проблема с авторскими правами: ИИ обучали на видео, которые принадлежат разным правообладателям. С такими проблемами столкнулись и создатели нейросетей, которые генерируют картинки. На компанию Stability AI, разработчика Stable Diffusion, подали в суд за нарушение авторских прав, поскольку в датасет входили изображения, принадлежащие художникам.
Вот какие нейросети уже показали исследователи.
CogVideo. В мае 2022 года китайские разработчики представили нейросеть CogVideo с открытым кодом, которая умеет генерировать очень короткие видео с частотой восемь кадров в секунду. На ввод принимает текст или изображение.

Протестировать демо можно на сайте, но модель генерирует гифку: анимация занимает одну секунду и состоит из четырех кадров. Нейросеть уже устарела: выдает посредственные результаты, а на сложных запросах генерирует непонятное месиво.

Make-A-Video. В сентябре Meta представила нейросеть Make-A-Video, которая может генерировать ролики продолжительностью не более пяти секунд в низком качестве. На вход нейросеть принимает текстовое описание, изображения и видео.
Компания показала тестовые ролики в низком качестве с артефактами, дерганой анимацией и смазанными объектами. Доступ к модели пока так и не открыли, но некоторые разработчики успели записаться в лист ожидания.

Imagen Video. В октябре Google показала нейросеть, которая генерирует видео в разрешении до 1280×768 пикселей с частотой 24 кадра в секунду и продолжительностью до трех секунд. Она работает на основе диффузионной нейросети Imagen, которая генерирует картинки.
Сгенерированные видео неидеальны — на них много артефактов и шума. Компания отказалась делиться исходным кодом из-за опасений, что пользователи начнут генерировать опасный контент.


Phenaki. Одновременно с выходом Imagen Video Google показала другую модель, которая может генерировать по детальному описанию длинные видео до нескольких минут, а в теории — неограниченные по времени. Она работает на основе нейросети-трансформера. Проблема в том, что Phenaki может генерировать видео только в низком разрешении.
Разработчики планировали использовать Phenaki совместно с Imagen Video, чтобы получать видео в высоком разрешении, но пока не представили такой алгоритм. Модель также не появился в публичном доступе из-за опасений Google.

Dreamix. В феврале 2023 года специалисты из Google Research представили нейросеть, которая редактирует видео по текстовому запросу. Она может добавлять элементы, заменять объекты и перерисовывать их полностью. Алгоритм работает с видео в низком качестве.
Dreamix также может генерировать видео на основе картинки: заставить объект двигаться или собрать связный ролик из нескольких похожих изображений. Эту модель Google тоже не планирует выпускать.

Runway Gen-2. Первая версия модели Runway генерирует на основе видео и текстового описания, изменяя стилистику ролика. Попробовать нейросеть можно на сайте. В середине марта стартап Runway представил нейросеть Gen-2. Новая модель генерирует ролики продолжительностью в три секунды только по текстовому описанию — исходное видео не нужно.
Разработчики показали несколько коротких демо, а также предоставили доступ к модели отдельным разработчикам. Видео не отличаются реализмом, но артефактов и шума на них немного. Публичный доступ обещали открыть весной 2023 года.

Где можно сгенерировать видео самому
В марте 2023 года исследовательское подразделение китайской Alibaba DAMO Vision Intelligence Lab выпустило нейросеть c открытым исходным кодом ModelScope для генерации видео. Она использует диффузионную модель, схожую с алгоритмом Stable Diffusion.
Демо доступно публично. Нейросеть генерирует 2,5-секундные ролики с логотипом Shutterstock — убрать его не получится. Судя по всему, это происходит, потому что датасет, на котором обучали ModelScope, состоял из стоковых видео с вотермарками.
Как сгенерировать видео в ModelScope. Перейдите на Hugging Face, введите короткий запрос на английском языке, например, «конь бежит по океану», и нажмите Generate. С длинными и сложными промптами ModelScope не справится: либо не поймет вас, либо сгенерирует только часть.
В среднем ожидание составляет 10—15 минут. Если появляется ошибка, это означает, что серверы перегружены: кликайте на Generate несколько раз, пока не запустится генерация. Если сайт так и не заработает, попробуйте Replicate: там тоже ModelScope, а ролики генерируются за полминуты. Количество генераций ограничено, но лимиты достаточно большие: более 10 видео в сутки.

Видео получаются с артефактами, объекты размыты, а анимация дерганая. ModelScope часто не попадает в запрос. Но это единственная актуальная нейросеть, в которой можно попробовать сгенерировать видео по текстовому запросу в браузере.



Если вы обладаете навыками программирования, то установите модель напрямую — код доступен на сайте ModelScope. Для этого требуется 16 Гб оперативки и видеокарта с 16 Гб памяти.
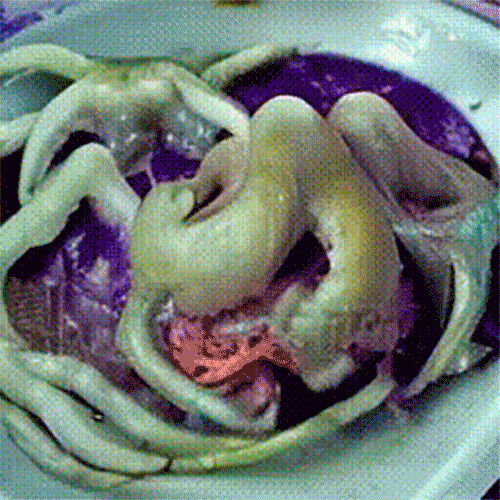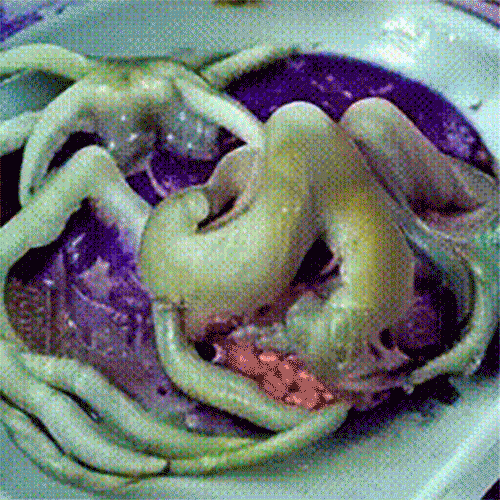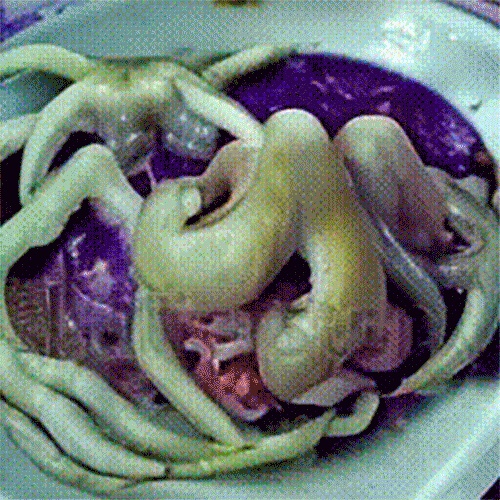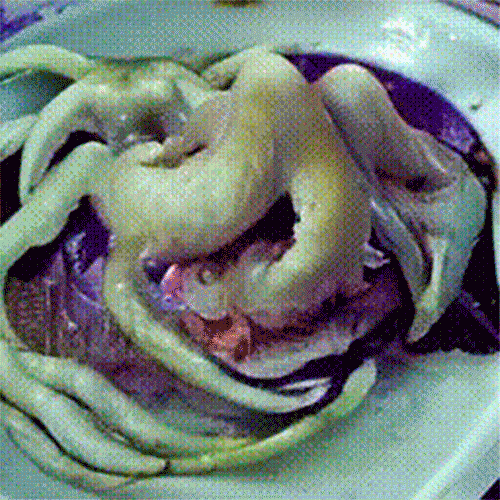
Что генерируют в ModelScope. Несмотря на то что качество генерации оставляет желать лучшего, пользователи нашли применение нейросети: там массово создают мемные видео.
Все началось с ролика, где Уилл Смит ест спагетти — выглядело это настолько пугающе и забавно, что люди массово стали генерировать видео, на которых знаменитости едят разные блюда. ModelScope «знает» многих известных людей: Илона Маска, Эмму Уотсон, Дуэйна Джонсона и других.

Генерациями делятся в разделе r/StableDiffusion на Reddit: многие объединяют несколько видео в один клип, чтобы получить сюжет. Некоторые сами озвучивают ролики или накладывают музыку.




Что нужно знать о нейросетях, которые генерируют видео
- Нейросети пока не могут генерировать видео на том же уровне, что картинки или текст. Видео получаются очень короткими, с артефактами и нестабильной анимацией.
- Далеко не все существующие модели можно попробовать. Компании опасаются открывать доступ к коду, поскольку боятся, что пользователи будут генерировать фейки или опасный контент.
- Те нейросети, которые можно опробовать, выдают неудачные результаты. В соцсетях нашли применение сгенерированным роликам пока только для мемов.
- Говорить о генерации консистентных видео пока рано. Но если нейросети продолжат развиваться таким же темпами, то уже через год ситуация может измениться.
Мы постим кружочки, красивые карточки и новости о технологиях и поп-культуре в нашем телеграм-канале. Подписывайтесь, там классно: @t_technocult.










description